HPCGame 2025 个人Writeup

Ribom / 690.62 pt 100, 100, 91.62, 89, 150, 22, 88, 0, 0, 0, 50, 0
这届本来是抱着学一学异构的想法来的,结果反而深陷OI题陷阱,拼尽全力无法战胜BUG(包括我的和评测机的),最后没时间了反而没玩到CUDA和NPU,而且又痛失30名了。
按WP要求保留了生成式AI使用声明:本次比赛借助了Github Copilot代码补全和deepseek大模型。Copilot部分没有聊天记录留存,deepseek聊天记录图片存放于附件deepseek文件夹中,正文中会出现部分整段生成内容。
A 签到
善用F12 CSS selector. 1898
B 小北问答 极速版
欢迎来到:deepseek秒一切时间
1. 鸡兔同笼
(填数字)
某厂的CPU采用了大小核架构,大核有超线程,小核没有超线程。已知物理核心数为12,逻辑核心数为16,大核数量为____,小核数量为____。
4, 8 超线程是一个逻辑核在等待指令期间可以把时间片给另外一个核,使得程序无法感知,效果上就是等效逻辑核翻倍,但是计算单元(比如浮点等)还是只有一个,所以可以看成大核小核,小核只有部分功能。 https://www.cnblogs.com/badboy200800/p/12641255.html
2. 编程语言
(填“是”或者“否”)
C语言中,假设有函数 void f(const void **p);,我们有 void **q;,请问不使用强制类型转换,直接调用 f(q) 是否符合 C 的规范?
否 我第一遍猜错了,怎么回事呢?
3. CPU Architecture
(填数字)
ARM架构的sve2指令集具有可变向量长度,且无需重新编译代码,就可以在不同向量长度的硬件上运行。sve2指令集的最小硬件向量长度是____,最大硬件向量长度是____。
128 2048 https://juejin.cn/post/7070872857315639332
4. MISC
(填数字)
fp4 是一种新的数字格式,近期发布的许多硬件都增加了对 fp4 的支持。SE2M1(一位符号,两位 exponent,一位 mantissa)条件下,fp4 能精确表示的最大数字是____,能精确表示的最小的正数是____。
【注意,模仿IEEE风格或OCP Microscaling Formats标准的结果都视为正确答案】
6 0.5
https://arxiv.org/pdf/2310.16836 https://cloud.tencent.com/developer/article/2335311 我一开始是对着第一篇文章里的图看的,似乎怎么看都应该是1, 12,但是不对。后来查到第二个博客才发现可能有不同的归一化方式,虽然不知道为什么
5. 储存
(填写字母,字母之间不要空格)
ZNS(Zoned Namespaces)SSD是一种新型储存设备,关于传统SSD与ZNS(Zoned Namespaces)SSD的行为差异,以下哪些说法是正确的?(多选)
A. 当写入一个已有数据的位置时,传统SSD会直接原地覆盖,而ZNS SSD必须先执行Zone Reset操作
B. 传统SSD的FTL会维护逻辑地址到物理地址的映射表,而ZNS SSD可以显著简化或消除这个映射过程
C. 当可用空间不足时,传统SSD会自动触发垃圾回收,而ZNS SSD需要主机端主动管理并执行显式擦除
D. 传统SSD一般支持任意位置的随机读取,而ZNS SSD只支持顺序读取
E. 传统SSD通常需要较大比例的预留空间(Over-Provisioning),而ZNS SSD可以将这部分空间暴露给用户使用
BCE
我直接给deepseek了:
以下是各选项的分析:
A. 当写入一个已有数据的位置时,传统SSD会直接原地覆盖,而ZNS SSD必须先执行Zone Reset操作
错误:传统SSD不会直接原地覆盖数据,而是通过FTL将新数据写入新的物理位置,并标记旧数据为无效。ZNS SSD确实需要执行Zone Reset操作来擦除整个Zone后才能重新写入。
B. 传统SSD的FTL会维护逻辑地址到物理地址的映射表,而ZNS SSD可以显著简化或消除这个映射过程
正确:传统SSD依赖FTL来管理逻辑地址到物理地址的映射,而ZNS SSD通过Zone的划分和顺序写入,可以简化或消除复杂的映射过程。
C. 当可用空间不足时,传统SSD会自动触发垃圾回收,而ZNS SSD需要主机端主动管理并执行显式擦除
正确:传统SSD会自动触发垃圾回收来回收无效数据块,而ZNS SSD需要主机端主动管理Zone的擦除和写入。
D. 传统SSD一般支持任意位置的随机读取,而ZNS SSD只支持顺序读取
部分正确:传统SSD确实支持任意位置的随机读取,但ZNS SSD也支持随机读取,只是写入必须按顺序进行。因此,ZNS SSD并非“只支持顺序读取”。
E. 传统SSD通常需要较大比例的预留空间(Over-Provisioning),而ZNS SSD可以将这部分空间暴露给用户使用
正确:传统SSD需要预留空间来优化性能和延长寿命,而ZNS SSD通过主机端管理Zone,可以将这部分空间暴露给用户使用。
正确答案:B、C、E
6. OpenMPI
(填写patter为x.y.z,版本号的前缀v省略)
OpenMPI 是一个开源的消息传递接口 (MPI) 实现,在高性能计算领域被广泛使用。截至2025年1月18日,OpenMPI 发布的最新稳定版本为 _____,在此版本的 OpenMPI中内置使用的 PRRTE 的版本为 _____。大家可以了解一下PRRTE的作用,OpenMPI 4 到 5 的架构变化,还挺有趣的。
先去官网上找最新stable版本号 https://www.open-mpi.org/software/ompi/v5.0/
然后对着版本号去github仓库找对应commit里的changelog https://github.com/open-mpi/ompi/blob/v5.0.6/docs/release-notes/changelog/v5.0.x.rst
7. RDMA
(填写字母,字母之间不要空格)
RDMA 是一种高性能网络通信技术,它允许计算机直接访问远程内存,从而大大降低了通信延迟和 CPU 开销。目前,主流的 RDMA 实现包括 InfiniBand、RoCE、RoCEv2 和 iWARP。下图中从左到右的四列展示了四种 RDMA 实现的架构图,请你说出按照从左到右的顺序,说出下图中的四列分别对应了什么 RDMA 的实现架构_____。
A: RoCE B: RoCEv2 C: iWARP D: InfiniBand
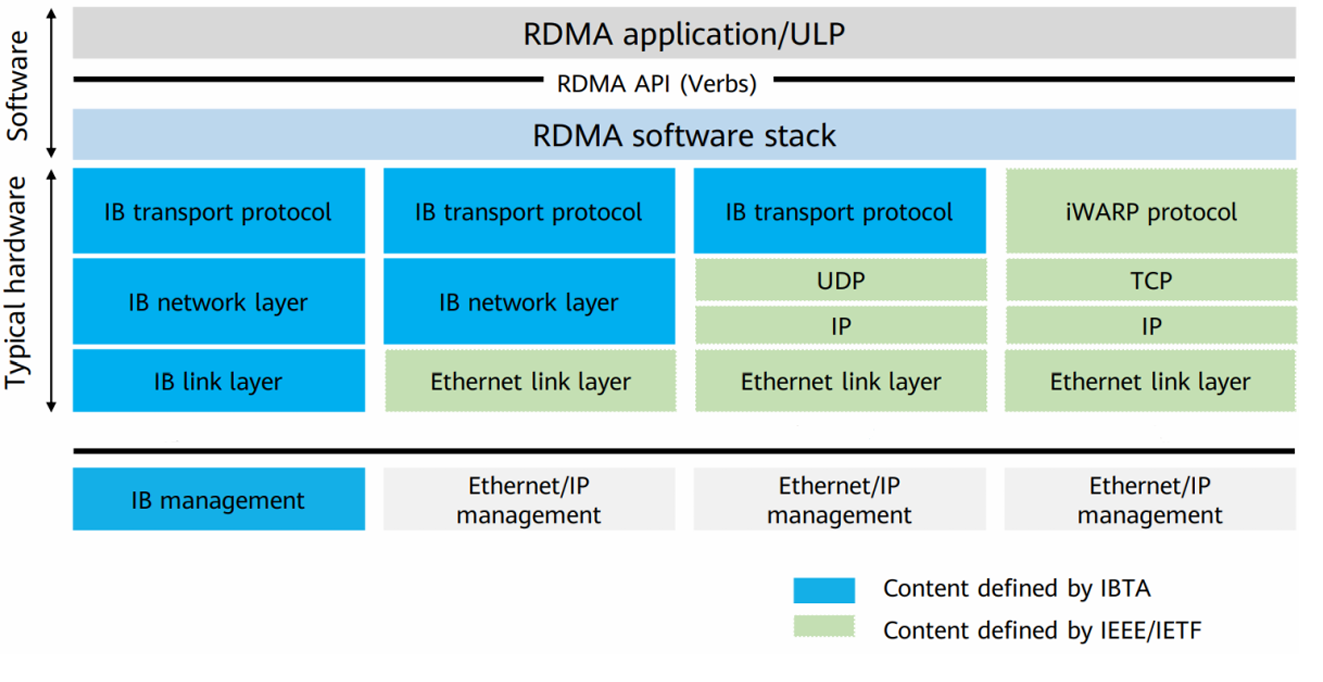
DABC
deepseek
请解释下面四种RDMA架构的区别:A: RoCE B: RoCEv2 C: iWARP D: InfiniBand
RDMA(Remote Direct Memory Access)是一种网络通信技术,允许计算机直接从远程主机的内存中读取或写入数据,而无需CPU的干预。以下是四种RDMA架构的区别:
---
### **A. RoCE(RDMA over Converged Ethernet)**
- **定义**:RoCE是一种基于以太网的RDMA协议,允许在以太网上实现RDMA功能。
- **特点**:
- 运行在以太网(Ethernet)上,使用以太网帧传输数据。
- 支持链路层(Layer 2)的RDMA通信。
- 需要无损网络(Lossless Network)支持,通常依赖PFC(Priority Flow Control)和ECN(Explicit Congestion Notification)来避免丢包。
- 适用于数据中心内部网络。
- **优点**:
- 利用现有的以太网基础设施,成本较低。
- 性能较高,延迟较低。
- **缺点**:
- 对网络配置要求较高,需要支持无损网络。
---
### **B. RoCEv2(RDMA over Converged Ethernet version 2)**
- **定义**:RoCEv2是RoCE的升级版本,支持在IP网络上运行。
- **特点**:
- 运行在UDP/IP协议之上(Layer 3),可以在广域网(WAN)中运行。
- 支持跨子网的RDMA通信。
- 仍然需要无损网络支持,依赖PFC和ECN。
- **优点**:
- 比RoCE更灵活,支持跨子网通信。
- 保留了RoCE的高性能和低延迟特性。
- **缺点**:
- 对网络配置要求仍然较高。
---
### **C. iWARP(Internet Wide Area RDMA Protocol)**
- **定义**:iWARP是一种基于TCP/IP的RDMA协议。
- **特点**:
- 运行在TCP/IP协议栈上(Layer 4),支持广域网(WAN)通信。
- 不需要无损网络支持,可以在普通以太网上运行。
- 通过TCP的可靠传输机制保证数据完整性。
- **优点**:
- 兼容性高,可以在现有IP网络上运行。
- 对网络配置要求较低。
- **缺点**:
- 由于依赖TCP/IP协议栈,性能(延迟和吞吐量)通常低于RoCE和InfiniBand。
---
### **D. InfiniBand**
- **定义**:InfiniBand是一种高性能网络协议,专为RDMA设计。
- **特点**:
- 使用专用的InfiniBand网络硬件和协议栈。
- 支持极低的延迟和极高的吞吐量。
- 提供原生的RDMA支持,无需依赖以太网或TCP/IP。
- 需要专用的InfiniBand交换机和网卡。
- **优点**:
- 性能最优,延迟最低,吞吐量最高。
- 专为高性能计算(HPC)和数据中心设计。
- **缺点**:
- 成本较高,需要专用硬件。
- 部署复杂,不适合普通以太网环境。
---
### **总结对比**
| 特性 | RoCE | RoCEv2 | iWARP | InfiniBand |
|-----------------|--------------------|--------------------|--------------------|--------------------|
| **网络类型** | 以太网(Layer 2) | 以太网 + IP(Layer 3) | TCP/IP(Layer 4) | 专用InfiniBand网络 |
| **是否需要无损网络** | 是 | 是 | 否 | 是(原生无损) |
| **跨子网支持** | 不支持 | 支持 | 支持 | 支持 |
| **性能** | 高 | 高 | 中等 | 最高 |
| **成本** | 中等 | 中等 | 低 | 高 |
| **部署复杂度** | 中等 | 中等 | 低 | 高 |
- **RoCE/RoCEv2**:适合以太网环境,性能高,但对网络配置要求较高。
- **iWARP**:兼容性好,适合普通IP网络,但性能较低。
- **InfiniBand**:性能最优,但成本高,适合高性能计算场景。
还是有点长,提取关键字:
首先iwarp有自己的传输层,甚至图上直接有它的名字。 剩下一个基于IP协议的就只有RoCEv2,基于UDP的。 然后我们可以猜到RoCE一代也是基于以太网的,只是有自己的传输层。 最后是inifiniband,连网络层都是独有的。
8. HPCKit
(填数字序号,数字之间不要空格)
HPCKit 是针对鲲鹏平台深度优化的HPC基础软件,请选择以下组件的具体作用。
A. BiSheng B. HMPI C. KML D. KBLAS E. EXAGEAR
选项:
- 高性能数学计算加速库
- 基础线性代数过程库
- 高性能通信库
- X86到ARM的二进制指令动态翻译软件
- 编译器套件
53124
deepseek
以下是HPCKit组件及其具体作用的匹配:
- **A. BiSheng**:**5. 编译器套件**
BiSheng是针对鲲鹏平台优化的编译器套件,用于将源代码编译为高效的ARM架构可执行文件。
- **B. HMPI**:**3. 高性能通信库**
HMPI是针对鲲鹏平台优化的MPI(Message Passing Interface)实现,用于支持高性能计算中的分布式通信。
- **C. KML**:**1. 高性能数学计算加速库**
KML(Kunpeng Math Library)是鲲鹏平台上的高性能数学计算加速库,提供优化的数学函数和算法。
- **D. KBLAS**:**2. 基础线性代数过程库**
KBLAS是鲲鹏平台上的基础线性代数库,提供高效的BLAS(Basic Linear Algebra Subprograms)实现。
- **E. EXAGEAR**:**4. X86到ARM的二进制指令动态翻译软件**
EXAGEAR是一种二进制翻译工具,可以在ARM平台上运行为X86架构编译的程序。
---
### 最终匹配结果:
- **A. BiSheng** → **5. 编译器套件**
- **B. HMPI** → **3. 高性能通信库**
- **C. KML** → **1. 高性能数学计算加速库**
- **D. KBLAS** → **2. 基础线性代数过程库**
- **E. EXAGEAR** → **4. X86到ARM的二进制指令动态翻译软件**
大概看一眼没什么错误。其中EXAGER稍微查了一下,是一种虚拟化技术,确实是需要异构的指令翻译。
9. CXL
(填数字,保留两位有效数字)
在传统的AI/ML计算中,模型训练和推理通常涉及大量的数据传输,尤其是在需要在CPU和GPU之间频繁交换数据时。例如,一个深度学习模型的训练任务可能包含以下步骤:
- 数据加载��和预处理在CPU上完成。
- 预处理后的数据从CPU传输到GPU进行训练计算。
- 训练完成后,模型更新结果传回CPU进行后续处理。
假设有以下条件:
- 每次批处理需要传输的数据量为1GB。
- GPU每秒钟可以完成10次这样的批处理。
- 传统架构下,CPU到GPU的PCIe传输延迟为50μs,传输带宽为10GB/s。
- CXL架构下,传输延迟降至10μs,且数据访问可直接完成,无需显式传输。
假设总训练任务包含10000次批处理。比较传统架构和CXL架构下完成任务所需的总时间,计算加速比(传统架构时间 / CXL架构时间),保留两位有效数字。
(该题基于理想化模型,与真实情况并非完全符合)
2.0
其实没太懂CXL原理,但这题被deepseek秒了(
我朴素的理解,原本是需要CPU拷贝到GPU上,完成计算,再拷贝回来,但和下一批数据流水线拷贝过去的时间可以重合。考虑到单位任务数据拷贝和计算需要的时间一样,GPU其实有一半时间在空转。 现在可以去除拷贝的过程,计算同时就可以拷贝另一部分数据(或者也可能不需要拷贝?不太懂直接完成是什么含义)总之就是没有空转时间。 传输延迟(应该是指发出指令到拷贝之间的时间)低了几个量级,忽略不计。 所以结果是2.0 不过我一开始交的是1.5,是考虑数据拷贝过去和回来两个事情是分开发生的,和计算也没有流水线化。
10. 量子计算
(填数字,小数形式)
量子计算是一种基于量子力学原理的计算方式,它利用量子比特的叠加态和纠缠态来进行计算,被认为是下一代计算技术。加速量子计算的模拟、数据处理等负载也是目前高性能计算领域的热点之一。
初始状态为∣0⟩\ket0∣0⟩的量子比特,经过一次Hadamard门(H门)操作后,测量得到∣0⟩\ket0∣0⟩的概率是______?经过两次Hadamard门(H门)操作后,测量得到∣0⟩\ket0∣0⟩的概率是______?
0.5, 1
https://en.wikipedia.org/wiki/Quantum_logic_gate
只懂一点点量子力学皮毛。总之这个H门的矩阵大约是[1,1;1,-1]/sqrt2的形式,作用于量子比特后得到的状态量在原基底投影的平方即为概率。简单计算可得。(H门作用两次状态还原)
C. 不简单的编译
题面给了一个简单的C计算卷积的程序(包括runner和一个函数)。我们可以自选语言(C/Fortran/C++)、编译器(amd, intel, nvidia, gcc, llvm)和编译选项,加速程序。最终提交主要包括一个CMakeLists.txt和修改后的filter.F90(它扩展名怎么不是C呢,很奇怪吧)
程序很短,我直接贴过来:
void filter_run(double x[113][2700], double wgt[113][1799], int ngrid[113], int is, int ie, int js, int je)
{
double tmp[ie - is + 1];
for(int j = js; j <= je; j++){
int n = ngrid[j];
int hn = (n - 1) >> 1;
for(int i = is; i <= ie; i++){
tmp[i - is] = 0;
for(int p = 0; p < n; p++)
tmp[i - is] += wgt[j][p] * x[j][i - hn + p];
}
for(int i = is; i <= ie; i++)
x[j][i] = tmp[i - is];
}
}
我尝试让deepseek改了一个fortran版本,之后再改了改,最终是长这样,注意函数声明部分需要保持兼容,主要是行列互换(fortran是列优先的)传值变量的value声明(Fortran默认是传引用的)以及C-binding(默认符号gfortran会小写加个_,ivf会�纯大写,和调用不兼容)。有少部分循环逻辑被deepseek改了,我看好像改了更快就没动。并且注意。此外我还加了强制向量化内层循环的声明,不过不知道有没有生效。
subroutine filter_run(x, wgt, ngrid, is, ie, js, je) bind(C, name='filter_run')
!use, intrinsic :: ISO_C_BINDING
implicit none
integer, intent(in), value :: is, ie, js, je
integer, intent(in) :: ngrid(113)
double precision, intent(inout) :: x(2700, 113)
double precision, intent(in) :: wgt(1799, 113)
integer :: i, j, p, n, hn, len
double precision :: tmp(ie - is + 1)
len = ie - is + 1
do j = js + 1, je + 1
n = ngrid(j)
hn = (n - 1) / 2
! Initialize tmp array
do i = 1, len
tmp(i) = 0.0d0
end do
! Compute weighted sum
do p = 1, n
!DEC$ IVDEP
!DEC$ vector always
do i = is, ie
tmp(i - is + 1) = tmp(i - is + 1) + wgt(p, j) * x(i - hn + p, j)
end do
end do
! Update x array
do i = is, ie
x(i + 1, j) = tmp(i - is + 1)
end do
end do
end subroutine filter_run
之后只试了gcc和intel,后来发现intel加上-xHost之后提速极其明显,可能是用了向量化指令。可惜没拿满,可能有些优化选项漏了(要说intel fortran真强吧)。
下面的CMakeLists.txt(尝试用deepseek,但是好像没太多有用的,只留了这些)
cmake_minimum_required(VERSION 3.20)
project(FilterProject LANGUAGES CXX Fortran)
# set(CMAKE_C_COMPILER "icx")
# set(CMAKE_CXX_COMPILER "icpx")
# set(CMAKE_BUILD_TYPE Release)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -O2")
set(CMAKE_Fortran_FLAGS "${CMAKE_Fortran_FLAGS} -O2 -xhost")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -O2")
add_executable(program main.cpp filter.F90)
set_source_files_properties(filter.F90 PROPERTIES LANGUAGE Fortran)
D. 最长公共子序列
最大数据规模为1M,环境为arm。可以用OMP跑8个线程。
这个是经典动态规划算法题,可以写出转移方程(如果匹配等于左上+1,如果不匹配等于上面和左面�取最大的)。我用了一个经典的并行算法,就是反对角线式并行(或者转45度并行),当规模足够大时,一条反对角线上的不同位置没有数据依赖,可以同时计算。注意反对角线问题规模在开头和结尾是很低的,只有规模足够大的时候线程才有优势,所以需要类似#pragma omp parallel for if (imax - imin > 16)。另外空间方面,最大的1Mx1M是无法存储整个动态规划表的,好在每条反对角线只和前两轮有关,最少只需要两个buffer(可以直接在某一个buffer上更新)
这个题我后来陷入了一种想要优化却发现越改越慢的境地,比较尴尬。比如我曾经尝试把三个buffer改成两个buffer,就变慢了(仔细想想可能是false sharing了)。这个题评测机也不太稳定,加上pod比较难开,后来就没有进一步优化了。
E. 着火的森林
这题是一个大型模拟,需要模拟一个二维图的状态转移。MPI,4节点共64进程。
因为数据很大,基本策略就是分布式存储。第一个进程读数据,然后用MPI分发给各个进程,我是按行分割切片的,这样和IO的顺序一致,程序处理也简单,第i个进程处理前i/64块。
分配内存时多分配两行作为ghost cell,也作为进程间信息交换的缓冲区。考虑到需要临界格信息的只有火焰扩散一步,我们只在这一步之前进行信息交换,并且尽量使用MPI_SendrecvCollective method进行。
此外,我们最好期待同一个节点上的16个进程是连续的,以尽可能减少节点间通信次数(我本来��考虑用某种共享内存机制让同节点不通信的,不过后来发现不需要了)。我最后是采取把hostname hash之后发给rank 0进程,然后按hostname, rankid字典序排序确定block数。
另外MPI debug有点不太好搞,因为多个进程同时输出会把控制台弄得乱七八糟,我最终用了一个非常神必的gadget:
#ifdef DEBUG
usleep(rank_id * 10000);
std::cerr << "Debug message" << std::endl;
#endif
- 这题我开Copilot做的,眼睁睁看着他自己就把MPI调用补全了,非常惊艳。
- 这题大战评测机空格换行BUG,拼尽全力无法战胜;后来发现基本没改的代码提交了几次之后AC了,如此成绩令人汗颜!
- 为了确保正确,我还自己写了一个streamlit可视化模拟程序盯帧了半天,最后发现新交的提交啥也没改就过了。
F. 雷方块
这,只拿了11%也要写吗?算了写吧,毕竟写了一天半,拼尽全力无法战胜。
第一轮提示放出来我才意识到这个可以转化为mod3线性方程组,系数矩阵的边长是n1*n2,对角线距离为0,正负1,正负n1处分别对应原点和左右上下,如果不为空块则为1,其余位置为0。另外注意到矩阵是对称的(两个相邻块点一个必然激活另一个),并且空块对应的作用等价于一行一列全零。很接近关灯问题(关灯是mod2),然后说是朴素高斯消元可以拿满,�那就……消吧?
首先是存储问题,这个题很明显是稀疏矩阵,不压缩是存不下的。我最后考虑行压缩存储,每行建立一个vector(n1*n2 - [零元素数量]个),消去了空格对应的纯零行列(这个选择不一定正确),然后每个行内也是一个vector(大概3n1+k,k是个常数),只分配这么大是因为在消元为上三角的过程中,元素只会出现在对角线左侧n1以内和右侧2*n1以内(+k是为了保证一定容差,担心有些零元素造成不稳定情况导致传播的稍远了一点)。消元就是朴素的消元 + 主元替换(经常出现0行),消元的复杂度是n1*n2 * n1 * n1(全部行需要消去下方行,但下方行只有大概n1行非零,每行大约只有2*n1非零元素)。本地profiling表示代回过程和消元相比可以忽略不计。复杂度正确,但还是慢了几十倍,应该至少有三到四个优化点没想到。
- 最后提交的版本还没改完,case2/3能跑到90s/170s左右,不知道为什么会WA,本地测试出现结果校验不对的情况都是消出了纯0行,说明解不唯一,我的程序还没有处理这种情况。但题目说解是唯一的,到时候看看官方会不会放数据出来。
- 结束之后我意识到我开始把纯零行列删掉不一定明智,因为这会破坏【元素全部排列在偏移对角线】这条性质,也破坏了原来矩阵可以按n1分块处理的特性。按理来说三对角阵可以用追赶法消元,虽然没有仔细研究但这种方法有可能不需要重新定义主元,也更利于向量化和并行(不过如果有零元素会不会有些地方除不了?)。
- 也是结束之后,看rabi老师说的才知道,要考虑对齐和avx512优化,会��有数量级提升。我写上头的时候光验证正确性了,没考虑清楚顶层设计问题,所以相当于白白坐牢,心服口服了。
- 顺便我的代码在几个版本之前还不会WA的,那时候还没上OMP,看起来给消元过程中第二轮循环可并行,上OMP之后能快1/3左右,但那个不会WA的版本我没有复制一份,也没git版本管理,可能亏了20-30分。
G. TopK
是尝试用Julia写一个TopK算法。不熟Julia,所以就直接用原来的partialsortperm查文档写了个最简单的分块并行,第一次运气巨好拿了44%。这也要写吗?.jpg
K. board
是要修改一个挖矿代码。这个题比较松,大概改了这几个优化点吧:
- 但是每次算完hash之后和全部10个目标都匹配一次(算hash比较昂贵,比较前缀是简单的)
- context每个线程内只创建一次即可。
- 线程通信模型用pthreads互斥锁加条件变量,前缀pool只读传入不加锁,只在写入结果时加锁,写入完成后触发条件变量。主线程按顺序读取并检查条件变量,大概是下面的范式:
// child threads
pthread_mutex_lock(&address_key_pool[itask].lock);
// maybe two threads find at the same time
if (!address_key_pool[itask].found)
{
address_key_pool[itask].found = true;
memcpy(address_key_pool[itask].privateKey, random_pool + random_counter, 32);
memcpy(address_key_pool[itask].address, address.c_str(), address.size());
pthread_cond_signal(&address_key_pool[itask].cond);
}
pthread_mutex_unlock(&address_key_pool[itask].lock);
// main threads
for (int itask = 0; itask < NTASKS; itask++)
{
pthread_mutex_lock(&address_key_pool[itask].lock);
while (address_key_pool[itask].found == false)
{
pthread_cond_wait(&address_key_pool[itask].cond, &address_key_pool[itask].lock);
}
std::cerr << "Task " << itask << " found" << std::endl;
pthread_mutex_unlock(&address_key_pool[itask].lock);
}
画板部分我也附上代码了,改的不多,主要是前缀匹配改成只匹配3-6字符,然后前2个字符在一定容差范围内和可允许的颜色比较(我这里颜色只& 0xf8之后再比较,相当于扔掉3个LSB)。我一开始还尝试实现一个线程安全队列传入job,可惜我cpp写的实在太菜了,拼尽全力无法战胜Segfault。后来发现扔了几个LSB之后已经够快了,甚至空转期很长,就放弃了优化。(后来意识到群友都打表的,这才是高手.jpg)
图片预处理方面,我选择GIMP缩放查看效果 + python PIL减色处理(我觉得让程序匹配几千个只出现一次的像素还是太抽象了,我后来按颜色出现频率减色到512色(后来意识到减色算法可能用k-means算法会更好,但是懒得写了))